Puma.NET is a wrapper library for Cognitive Technologies CuneiFrom recognition engine that makes it easy to incorporate OCR functionality in any .NET Framework 2.0 (or higher) application. The API is provided through a number of simple classes. High performance and accurate results of recognition can be achieved via a couple of lines of code.
Reference documentation and sample Windows Forms application is available making it easier getting started developing with Puma.NET.
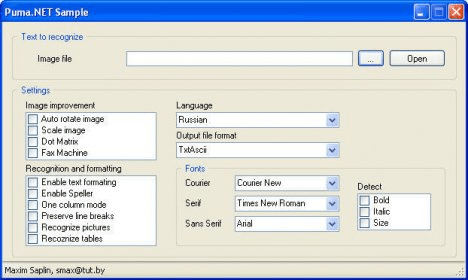
The OCR capabilities:
1. Omni Font technology – recognition of almost all printed fonts
2. 27 languages supported (English, German, Croatian, Polish, Danish, Portuguese, Dutch, Digits, Czech, French, Romanian, Hungarian, Bulgarian, Slovenian, Lettish, Lithuanian, Estonian, Turkish, Russian, Swedish, Spanish, Italian, Russian-English, Ukrainian, Serbian)
3. Spell checking and automatic corrections
4. Detecting font formatting (sizes, italics, boldness, underline, sans, courier)
5. Fragmentation and preserving document structure: paragraphs, spaces, images, tables etc.
6. Improved recognition of skewed and speckled images, special modes for dot-matrix and fax papers’ scans
7. Input image formats: BMP, GIF, EXIG, JPG, PNG and TIFF
8. Output formats: TXT, RTF, HTML
Comments